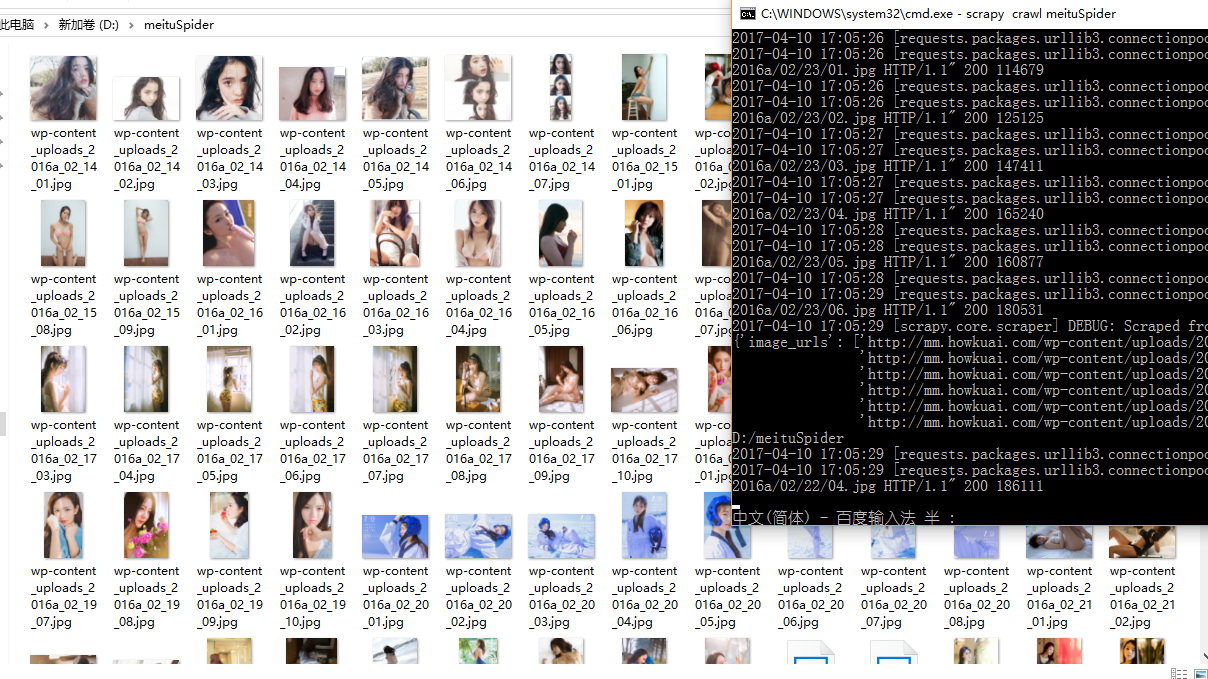
用爬虫抓取美女图片下载到本地,终于能用技术造福群众了,现在讲解抓取妹子图
开始项目
scrapy startproject meitu
打开items文件,新建一个items,这里这写一个image_urls
import scrapy
class MeituItem(scrapy.Item):
image_urls = scrapy.Field()
在spider目录下新建meitu.py 整体的思路是这样的:抓取第一页的数据,回调函数parse_test获取每个超链接,对获取的url发起请求回调函数parse_page再解析没张图片的src存入MeituItem 关键是要构造headers,不然就被发爬虫检测拦截了。
import scrapy
from meitu.items import MeituItem
from faker import Factory
f = Factory.create()
class meituSpider(scrapy.Spider):
name = "meituSpider"
start_urls = ['http://www.meizitu.com/a/list_1_1.html']
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.01',
'Accept-Encoding':'gzip,deflate,br',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'User-Agent':f.user_agent()
}
def start_requests(self):
urls = ['http://www.meizitu.com/a/list_1_%s.html' %s for s in range(1,10)]
for url in urls:
yield scrapy.Request(url=url,headers = self.headers,meta={'cookiejar':1},
callback=self.parse_test)
def parse_test(self,response):
page_urls = response.xpath('//div[@class="con"]//div[@class="pic"]//a//@href').extract()
for page_url in page_urls:
yield scrapy.Request(page_url,headers = self.headers,callback=self.parse_page)
def parse_page(self,response):
image_urls = response.xpath('//div[@id="picture"]//p//img//@src').extract()
item = MeituItem()
item['image_urls'] = image_urls
yield item
定义一个管道,对item里的urls遍历下载,同样的,在用requests去获取的时候带上headers,不然就被拦截了
import requests
from meitu import settings
import os
from faker import Factory
f = Factory.create()
class MeituPipeline(object):
def process_item(self, item, spider):
if 'image_urls' in item:#如何‘图片地址’在项目中
images = []#定义图片空集
dir_path = '%s/%s' % (settings.IMAGES_STORE, spider.name)
print(dir_path)
if not os.path.exists(dir_path):
os.makedirs(dir_path)
for image_url in item['image_urls']:
us = image_url.split('/')[3:]
image_file_name = '_'.join(us)
file_path = '%s/%s' % (dir_path, image_file_name)
images.append(file_path)
if os.path.exists(file_path):
continue
with open(file_path, 'wb') as handle:
response = requests.get(image_url, stream=True,headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.01',
'Accept-Encoding':'gzip,deflate,br',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Connection':'keep-alive',
'User-Agent':f.user_agent()
})
for block in response.iter_content(1024):
if not block:
break
handle.write(block)
return item
最后一步,打开settings文件,把管道的注解打开,再定义一个下载的路径
ITEM_PIPELINES = {
'meitu.pipelines.MeituPipeline': 300,
}
IMAGES_STORE = 'D:'
cd meitu
scrapy crawl meituSpider
成果